
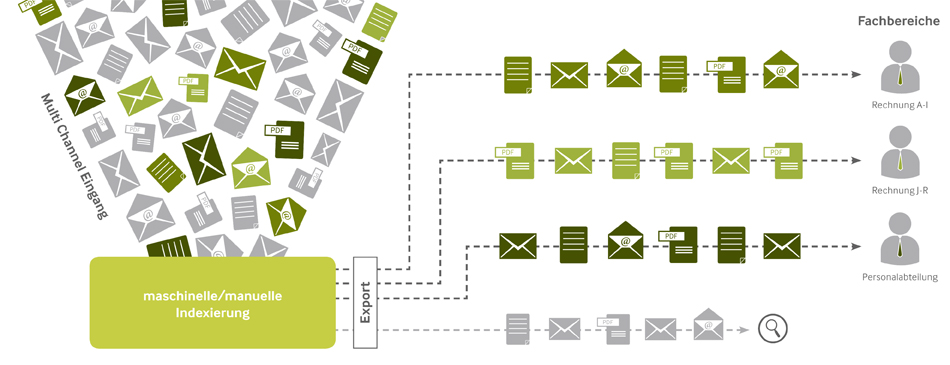
Im dritten Teil der Serie zum Input Management haben wir die einzelnen Prozessschritte etwas näher erläutert. Was im Modell noch recht einfach und einleuchtend erscheint, wird in der Umsetzung aber häufig zur Herausforderung. Natürlich haben viele Hersteller schon Lösungen in petto, die den Verantwortlichen das Leben sehr erleichtern. Allerdings sollte man sich nicht vorschnell in ein bestimmtes Angebot verlieben oder aus Bequemlichkeit beim bisherigen Anbieter bleiben. Denn bei der Auswahl einer passenden Softwarelösung gilt natürlich die Erkenntnis:
Technik ist nicht gleich Technik
Der Erkennungsprozess (OCR und Daten-Abgleich) liefert in der Regel durchschnittlich 70 bis 90 Prozent der für die weitere Zuordnung und Verbuchung benötigten Daten. Dabei hängt die Erkennungsqualität massiv von der Qualität des Beleggutes ab. Denn es macht natürlich einen gewaltigen Unterschied, ob maschinell ausgefüllte Vorlagen oder krakelige Notizen auf der Rückseite eines Umschlages erkannt werden müssen. Außerdem stehen je nach Strukturierungsgrad der Belege unterschiedliche Verfahren zur Verfügung. Ein Formular kann anders erkannt werden als ein handgeschriebener Freitext. Nicht zuletzt beeinflusst aber auch die Qualität der Stammdaten aus führenden Fremdsystemen wie ERP und CRM maßgeblich das Validierungsergebnis.
Insbesondere der zuletzt genannte Faktor wird in Projekten immer wieder unterschätzt. Damit die Wahl auf das richtige Produkt fällt, ist das Einsatzfeld verschiedener Verfahren näher zu beleuchten.
Die Anbieter von Input-Management-Systemen unterscheiden bei der Klassifikation layout- und inhaltsbasierte Verfahren. Die layoutbasierte Klassifikationsmethode eignet sich insbesondere für strukturiertes Beleggut wie Formulare. Für Freitextdokumente wird in der Praxis eher eine inhaltsbasierte Klassifikation vorgenommen. In diesem Umfeld kommen zunehmend auch selbstlernende Verfahren zum Einsatz. Damit wird die Fähigkeit der Software beschrieben, auf Basis der gemachten Fehler und der darauf erfolgten Korrekturen die Klassifikationsgenauigkeit kontinuierlich zu verbessern. Zusätzlich sind in einigen Produkten auch Algorithmen im Einsatz, welche die spezifischen Fehlerquellen der eingesetzten Klassifikationsalgorithmen kennen und ausschließlich dazu entwickelt wurden, diese zu korrigieren.
Unterschiedliche Klassifikationsmethoden
Aufbauend auf der Klassifikation der Dokumente erfolgt die Erkennung der auszulesenden Werte. Auch hierbei lassen sich verschiedene Verfahren unterscheiden. Altbewährt ist die regelbasierte Erkennung. Bei diesem statischen Verfahren wird ein Regelwerk erstellt, das in der Lage ist alle relevanten Felder auf einem Dokument zu finden und auszulesen. Dieses Verfahren eignet sich besonders für Belege mit hohem Strukturiertheitsgrad, die auch längerfristig keinen Änderungen von Layout oder Inhalten unterliegen. Jede stärkere Änderung an einem solchen Beleg bedarf einer Anpassung im Regelwerk. Darüber hinaus gibt es auch für die Erkennung und das Auslesen von Werten auf dem Beleggut selbstlernende Verfahren, die wiederum aus gemachten Fehlern und deren Verbesserung lernen und somit in Training und laufendem Betrieb die Erkennungsqualität steigern.
Eine weitere interessante Möglichkeit bieten einige Hersteller, deren Produkte eine systemseitige Identifikation von Dokumentenklassen ermöglichen. Bei diesem Verfahren wird dem System ein heterogener Stapel von Dokumenten geliefert. Dieser wird zunächst Volltext-OCR gelesen und daraufhin nach inhaltlichen Ähnlichkeiten gebündelt. Bei diesem Verfahren wird, im Unterschied zu den oben beschriebenen Verfahren, keine der identifizierten Dokumentenklassen vom Menschen angelegt oder vordefiniert. Viele vom System vorgeschlagene Dokumentenklassen können im Projekt direkt übernommen werden. Dies ist insbesondere dann sinnvoll, wenn im Projekt noch keine Dokumentenklassen definiert wurden.
Da die Verfahren verschiedene Stärken aufweisen, ist es mittlerweile üblich, mehrere Methoden auf das erfasste Beleggut anzuwenden. Die erzielten Ergebnisse werden miteinander abgeglichen und bei abweichenden Resultaten ein Ranking erzeugt. Dadurch wird die Wahrscheinlichkeit der korrekten Klassifizierung weiter erhöht.
Von technischen Prozessen und fachlichen Workflows
Betrachtet man den technischen Prozess, wird häufig auch von einem Scan-Workflow gesprochen. Über diesen werden in den Systemen durchlaufende Prozessschritte definiert. Dabei wird beispielsweise festgelegt, welche Wege und Analyseschritte ein Image, welches vom Scanner geliefert wird, durchlaufen muss und wie im Falle einer Nachbearbeitung verfahren werden soll. Typischerweise verfügen die meisten Systeme für diesen sehr technischen und innerhalb der Lösung stattfindenden Prozess über eine eigene Workflow-Komponente, die diesen Prozess steuert. Der Grund dafür liegt vor allem in der Performance, da die technische Prozess-Engine optimal auf das System abgestimmt werden kann. Was gerade bei hohen Dokumentenmengen deutlich bessere Leistungen zur Folge hat.
Der fachliche Workflow findet nachgelagert zum technischen Prozess statt. Hier werden beispielsweise Rechnungsfreigabeprozesse abgebildet. Diese Workflow-Lösungen haben einen deutlich stärkeren Anwenderfokus und bilden die Schnittstelle zur inhaltlichen Weiterverarbeitung der im ersten Teil ermittelten Daten. Der fachliche Prozess muss nicht zwingend vom Input-Management-System gesteuert werden, sondern kann beispielsweise in einem ECM-System erfolgen. Die Anbieter für Input Management haben dieses Segment mittlerweile für sich entdeckt und bieten zunehmend auch für diesen Bereich spezielle Lösungen an. Dieser Trend wird im Markt durch Partnerschaften von Input Management mit Workflow-Anbietern oder Übernahmen von Workflow-Anbietern sichtbar.
Monitoring zur Steigerung der Prozesstransparenz und -analyse
Aufbauend auf den Veränderungen bei den Workflow-Komponenten bietet das Monitoring weiteres Verbesserungspotenzial. Das Thema Monitoring muss im Falle der Input-Management-Lösungen ebenfalls von zwei Seiten betrachtet werden. Zum einen die technische Überwachung des Systems: Hier tritt insbesondere die Einhaltung der vorgesehenen SLAs in den Vordergrund. Damit ist die Kontrolle der Durchlaufzeiten des Posteingangs durch die Erfassung gemeint. Um den Grundstein einer schnellen Bearbeitung des Posteingangs beim Sachbearbeiter zu legen, muss in vielen Unternehmen eine tag-gleiche Verarbeitung des Posteingangs sichergestellt werden. Um diese überwachen und bei Störfällen schnell an der richtigen Stelle eingreifen zu können, ist das technische Monitoring der Systeme von Bedeutung. Die Anbieter am Markt haben diesen Bedarf erkannt und bieten zunehmend umfangreichere Monitoring-Oberflächen an, die eine immer einfachere und schnellere Interpretation der technischen Daten ermöglichen.
Zum anderen wird zusätzlich zum technischen Monitoring die Überwachung der fachlichen Abläufe eines Unternehmens immer wichtiger. Das Ziel dabei ist die Abbildung der gesamten weiteren Verarbeitung des Posteingangs aus dem Input-Management-System über alle zwischengelagerten Fremdsysteme bis hin zum Postausgang über das Output-Management-System und das Archiv. Hintergrund ist die Notwendigkeit einer lückenlosen Dokumentation der Bearbeitung, die Kontrolle der Durchlaufzeiten und die Identifikation weiterer Verbesserungspotenziale und Engpässe in der Bearbeitung. Die hierzu von einigen Anbietern entwickelten Cockpits bieten teils umfangreiche BI-Funktionalität innerhalb der Input-Management-Lösung. Grundlage für eine derart weitreichende Auswertung stellen aber immer die betrieblichen Rahmenbedingungen dar.