
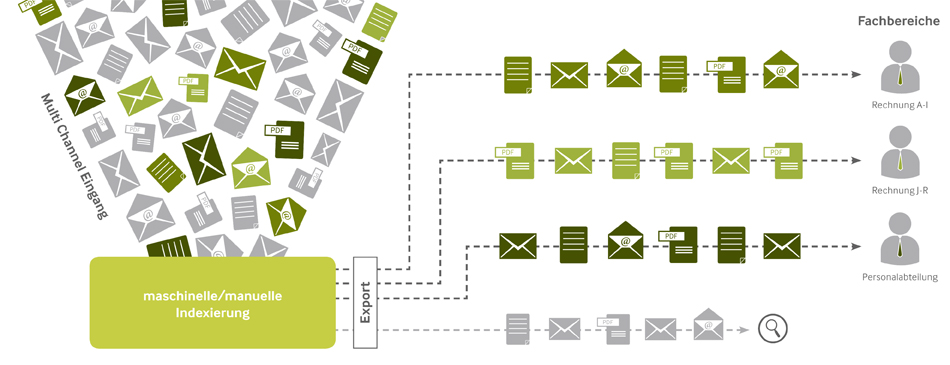
Selbst wer sich nur kurz mit dem Thema Input Management beschäftigt hat, erkennt schnell, warum dieser Unternehmensbereich nicht vernachlässigt werden darf. Den Handlungsbedarf zu erkennen ist also noch relativ einfach. Aber was macht nun im Einzelnen ein Input Management System aus und wie greifen die Bestandteile ineinander? Was für eine Herausforderung holt man sich ins Haus, wenn der Entschluss gereift ist, die eingehenden Informationen zeitgemäß zu verarbeiten?
Um Klarheit zu schaffen und damit auch etwaige Berührungsängste abzubauen erläutern wir Ihnen im Folgenden die einzelnen Prozessschritte. Im anschließenden Artikel wird ein besonderes Augenmerk auf dabei verwendete Technologien gelegt.
Technologische Bestandteile des Input Managements
Die Einführung einer Input Management Lösung umfasst mehrere Systemkomponenten, die in ihrem Zusammenspiel eine durchgängige Posteingangsbearbeitung ermöglichen und auch nur im Rahmen möglichst tiefer Integrationen bzw. Schnittstellen ihre volle Leistungsfähigkeit entfalten.
Beispiel E-Mail: Eine effiziente E-Mail Posteingangsbearbeitung setzt voraus, dass die E-Mail proprietär direkt vom E-Mail-Server „abgeholt“ und beispielsweise der elektronischen Klassifikation zugeführt werden kann. Häufig findet man immer noch veraltete beziehungsweise nicht durchgängige Verfahrensweisen vor, die aus aktueller Sicht völlig umständlich sind. Dabei werden eingegangene E-Mail vorübergehend in Bilddateien umgewandelt und dann einer OCR -Erfassung zugeführt, um daraus wieder eine OCR-lesbare Datei zu machen. Und das alles, obwohl die E-Mail ja bereits ein elektronisches Dokument ist, dass seinerseits schon fast ein in die Jahre gekommenes Medium ist und von modernen sozialen Medien zunehmend Konkurrenz bekommt. Ein strategisches, nachhaltiges Input Management bedarf somit moderner technologischer Komponenten und einer möglichst tiefen Integration in die Gesamtarchitektur.
Beschäftigt man sich mit der Produktauswahl, so kommt man früher oder später zur Philosophie- bzw. Strategieentscheidung: Setzt man auf „Best of breed“, also bestmögliche Lösung für die jeweils einzelnen Funktionsbereiche oder sucht man eine Produktsuite, die übergreifende Funktionsbereiche in einem System vereint. Ein Richtig oder Falsch kann nicht bestimmt werden. Vielmehr ist entscheidend, welche Systeme bereits bestehen. Muss also für ein durchgängiges Verfahren nur punktuell ergänzt werden oder startet ein Unternehmen auf der grünen Wiese? Um dies besser einschätzen zu können, muss man sich vor Augen führen, welche Komponenten ein Input Management beinhaltet.
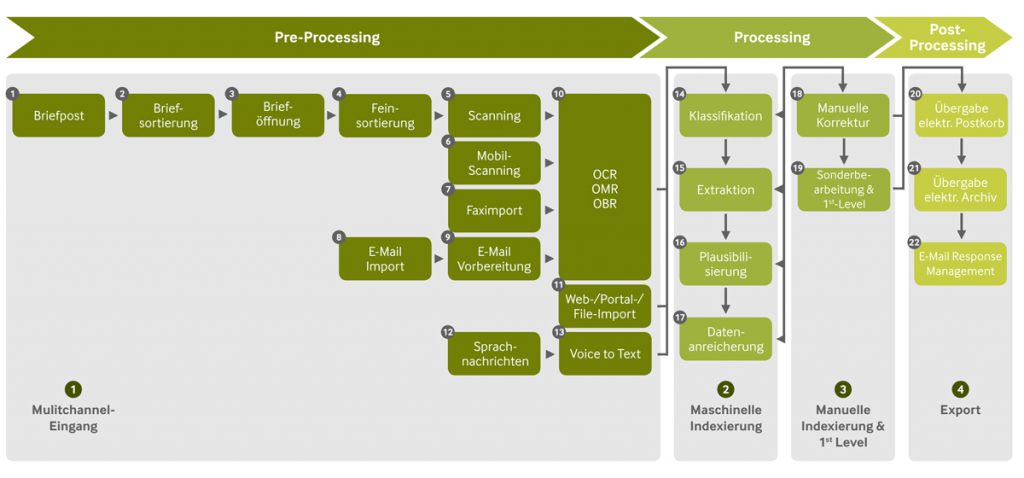
Hier wird zunächst in drei Abschnitte unterschieden. Der Begriff „Processing“ bedeutet nichts Anderes als „Verarbeitung“. Im Pre-Processing wird der Posteingang also für die Verarbeitung vorbereitet. Danach werden die erfassten Daten durch Software auf ihren Informationsgehalt geprüft und entsprechend digital gekennzeichnet. Im Post-Processing wird der so überprüfte Posteingang in die angeschlossenen IT-Systeme übergeben und den zuständigen Personen zugeführt.
Pre-Processing
Während im Bereich der Briefsortierung- und Öffnung maßgeblich mechanische Hilfslösungen zum Einsatz kommen (Einzelschritte 1 bis 4), beginnt in dieser Phase ab dem Scanprozess der wesentliche Softwareeinsatz (Einzelschritte 5 bis 13). Eine Scan-Software sorgt für das erste digitale Abbild im Scanprozess und bietet in diesem Verarbeitungsabschnitt Funktionen im Bereich der Bildkorrektur und Vorverarbeitung. Außerdem erfolgt in dieser Phase in der Regel eine erste Volltext-OCR, die ein gescanntes Abbild unter anderem Volltext-durchsuchbar macht.
Viele Scanner bringen diese Software bereits im Lieferumfang mit. Alternativ bieten häufig auch die klassischen DMS-Lösungen schon integrierte Scan-Clients an, mit denen gängige Hardware-Komponenten angesteuert und eingebunden werden.
Processing
Im Bereich des Processings findet die eigentliche „intelligente“ Bearbeitung der Dokumente statt. Im Vorfeld wird auf der Grundlage der eingehenden „Post“ ein Regelwerk erstellt. In diesem werden die Dokumente anhand ihrer Merkmale in Dokumentenklassen und Dokumententypen eingeordnet. Für jedes Dokument wird festgehalten, welche Attribute relevant für die weitere Bearbeitung sind. Die Erfassung der so bestimmten Metadaten erfolgt idealerweise automatisch, kann jedoch bei Bedarf auch manuell durchgeführt bzw. ergänzt werden. In dieser Phase greift somit ein Softwaremodul, das einerseits mit sogenannten Engines eine automatische Klassifikation und Extraktion ermöglicht. Das gleiche Modul beinhaltet jedoch auch Benutzeroberflächen zur manuellen Nachkorrektur von Indexdaten zum Dokument, also für die manuelle Eingabe durch Sachbearbeiter.
Post-Processing
Das Bearbeitungsschritt des Post-Processings schließt nahtlos an die Bearbeitung des Processings an. Letztlich geht es nun darum die im Processing ermittelten Indexdaten den weiteren Bearbeitungsstufen zuzuführen. Elementar ist hierbei also die Schnittstelle zu entsprechenden Drittsystemen.